

什麼是過度擬合 (Overfitting)?從生活化比喻到核心概念
想像一位學生為了應付考試,不選擇理解課本中的基本原理,而是把過去所有的考卷題目與答案死記硬背下來,連出題老師筆誤的錯字、角落的塗鴉都牢記在心。當考試來臨,題型稍有變動或提問角度不同,他立刻陷入混亂,完全無法應對。這不是因為他不努力,而是他的學習方式出了問題——記住的是細節,而非規律。在機器學習的世界裡,這種「學得太細、反而失去靈活應用能力」的現象,正是所謂的「過度擬合」。

在技術層面,過度擬合指的是模型在訓練資料上表現近乎完美,幾乎能精準預測每一個已知樣本。然而,這樣的高準確度往往來自於模型「記住了」訓練資料中的雜訊、異常值和隨機波動,而非真正掌握了背後的普遍規律。一旦面對全新的資料,例如測試集或真實世界的輸入,模型的預測準確度就會大幅滑落。換句話說,它缺乏「泛化能力」——也就是將所學知識遷移至未知情境的能力。一個真正優秀的機器學習模型,價值不在於它對舊資料多麼熟悉,而在於它面對新資料時是否依然可靠。
過度擬合的雙生兄弟:欠擬合 (Underfitting)
與過度擬合形成對比的,是另一個極端:欠擬合。如果過度擬合是學得太多太雜,欠擬合則是學得太少太膚淺。
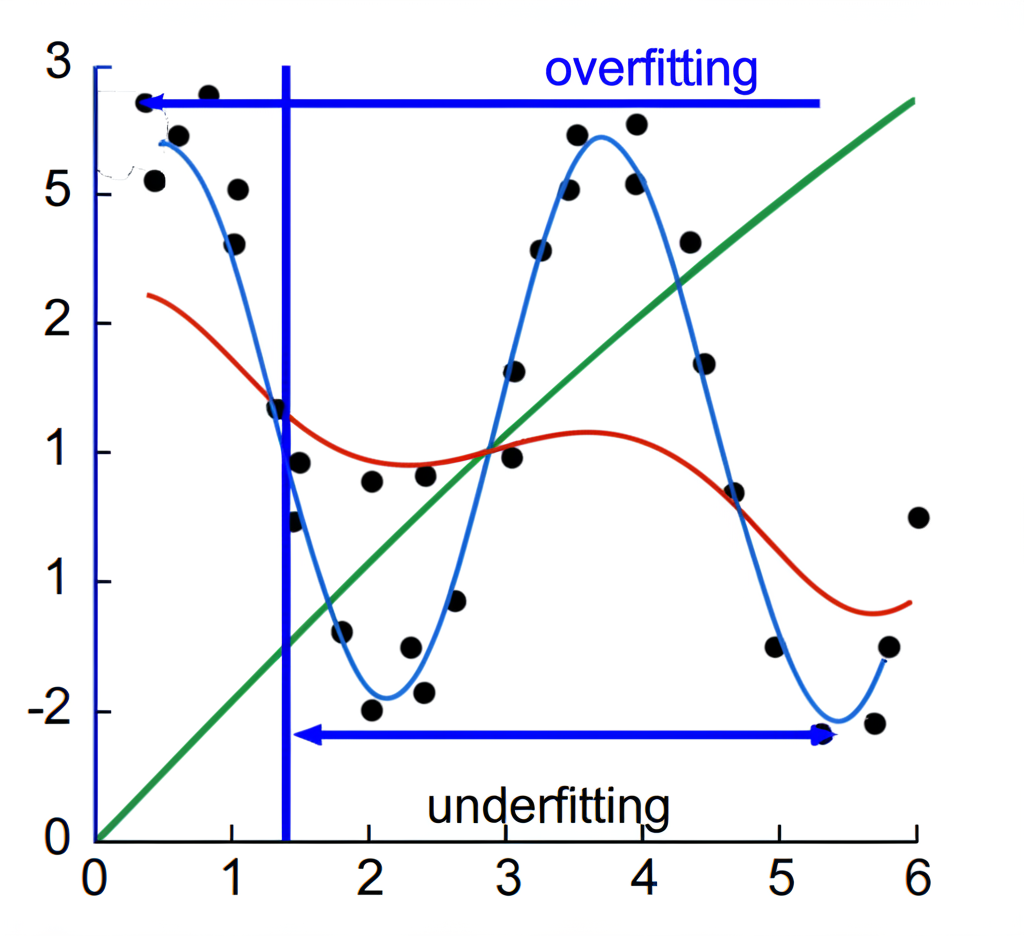
當模型結構過於簡單,無法捕捉資料中蘊含的基礎模式時,就會出現欠擬合。例如,使用一條直線去擬合本質上呈曲線分佈的數據,結果無論在訓練資料還是新資料上,預測效果都很差。它連原本就存在的資訊都沒學會,更別說舉一反三了。這種情況常見於模型容量不足、特徵不夠或訓練不充分。
透過視覺化的散點圖與擬合曲線,我們可以清楚區分三種模型狀態:
- 欠擬合:曲線過於僵硬或過於平直,無法貼近多數資料點,訓練與測試誤差都偏高。
- 理想模型:曲線柔順地反映資料的主要趨勢,不會過度彎曲,訓練與測試誤差都低且相近。
- 過度擬合:曲線像蛇一樣纏繞每一個訓練點,完美穿過所有資料,但面對新資料時預測偏差極大,測試誤差遠高於訓練誤差。
由此可見,過度擬合與欠擬合的根源截然不同:前者源於模型太強大、太複雜,後者則是模型太弱、太簡單。兩者都會導致模型失敗,只是失敗的方式不一樣。
模型為何會「過度學習」?探討過度擬合的四大主因
要有效預防過度擬合,必須先理解它從何而來。以下四個因素是導致模型「學過頭」的常見原因:
1. 模型複雜度過高
當模型擁有太多參數、過深的神經網絡層級,或是使用過於強大的演算法去處理簡單問題時,就容易陷入記憶陷阱。例如,用一個包含數百層的神經網絡去預測線性關係,等於拿大砲打蚊子。模型的自由度太高,足以完美擬合訓練資料的每一個細微波動,包括那些毫無意義的隨機雜訊。這就像讓一位精通微積分的學生去解小學加減法,反而可能因為過度分析而犯錯。
2. 訓練數據量不足
資料是模型學習的糧食。當訓練資料太少,卻要餵養一個龐大的模型,就如同只給孩子看三張貓的照片,就要他辨識世界上所有貓的樣子。模型會把這少數幾筆資料中的隨機特徵誤認為普遍規律。例如,在股票預測中,僅用三個月的數據訓練一個深度學習模型,很可能讓它記住的是特定事件的影響,而非市場的長期趨勢。資料量與模型複雜度之間必須取得平衡,否則模型只能「死記」,無法「理解」。
3. 數據中存在噪音
現實世界中的資料很少完美無瑕。標記錯誤、感測器誤差、輸入疏失,甚至是人為操作偏差,都會在資料中留下「雜訊」。當模型過於敏感,它不會分辨哪些是真實訊號、哪些是噪音,反而會努力去「解釋」這些錯誤。舉例來說,在醫療影像辨識中,若某些肺部X光片被錯誤標記為有腫瘤,過度擬合的模型可能因此學到錯誤的特徵關聯,進而影響未來的診斷準確性。
4. 特徵選擇不當或過多
特徵是模型理解世界的「語言」。若輸入的特徵太多、太雜,或包含大量無關變數,模型就容易被干擾。例如,在預測房價時加入「屋主星座」或「社區貓咪數量」這類無關特徵,雖然可能在訓練資料中偶然與價格相關,但毫無實際預測價值。這種「偽相關性」會讓模型產生虛假的學習路徑,最終導致過度擬合。精簡且有意義的特徵,才是模型穩健學習的基礎。
如何判斷模型是否已「過度擬合」?關鍵觀察指標
在模型開發過程中,及早發現過度擬合至關重要。以下三種方法能有效幫助我們診斷問題:
1. 觀察訓練集與測試集的性能差距
這是最直觀的指標。如果模型在訓練資料上準確率高達98%,但在測試資料上卻掉到70%,這明顯是警訊。訓練與測試表現之間的巨大落差,正是過度擬合的典型特徵。它顯示模型已經「背誦」了訓練資料,卻無法舉一反三。
2. 學習曲線 (Learning Curve) 分析
學習曲線將訓練誤差與驗證誤差隨著訓練進程或資料量增加的變化視覺化。若訓練誤差持續下降,但驗證誤差在某個點後開始上升,這代表模型開始記憶噪音。理想情況下,兩條曲線應逐漸收斂至相近的低誤差水平。若兩者之間存在穩定且明顯的差距,則模型極可能已過度擬合。
3. 交叉驗證 (Cross-Validation) 結果
交叉驗證透過將資料分成多個子集,輪流作為訓練與驗證資料,來評估模型的穩定性。如果模型在不同子集上的表現差異極大,表示它對特定資料過度敏感,缺乏一致性。穩健的模型應該在各種資料分割下都能維持相近的性能,這正是泛化能力的體現。
從根本解決:八大策略有效避免與緩解過度擬合
面對過度擬合,我們並非束手無策。以下八種策略已被廣泛驗證,能有效提升模型的泛化能力:
1. 增加訓練數據量
最直接也最有效的方式,就是提供更多資料。更多樣本能幫助模型識別出真正的模式,而非偶發的特徵。當實際資料有限時,「數據增強」是強大的替代方案。例如在圖像識別中,透過旋轉、鏡像、裁剪、調整亮度與對比,從單張圖片生成多種變形,大幅擴充訓練集。這不僅降低成本,還能提升模型對變化的容忍度。
2. 特徵選擇與特徵工程
與其讓模型自己摸索,不如主動提供高品質的輸入。特徵選擇能過濾掉無關或冗餘變數,降低模型複雜度;特徵工程則能透過數學轉換(如對數化、標準化)或領域知識,創造出更具解釋力的新特徵。例如,將「年收入」與「家庭人數」結合為「人均收入」,可能比單獨使用更有效。好的特徵設計,能引導模型走向正確的學習路徑。
3. 降低模型複雜度
面對簡單問題,不應使用過度複雜的工具。減少神經網絡的層數或神經元數量、選擇線性模型而非非線性模型、限制決策樹的深度,都是降低複雜度的實際做法。這不是削弱模型,而是讓它更專注於核心規律,避免陷入細節迷宮。
4. 正則化 (Regularization)
正則化是在損失函數中加入懲罰項,限制模型參數的成長,從而抑制過度擬合。常見方法包括:
- L1 正則化(Lasso):促使部分特徵的權重歸零,達到自動特徵選擇的效果。
- L2 正則化(Ridge):讓所有權重均勻縮小,避免任何單一特徵主導預測。
- Dropout:在神經網絡訓練中隨機關閉部分神經元,強制模型分散學習,不依賴特定節點。
這些技術如同為模型加上「學習紀律」,防止它走偏。
5. 提前停止 (Early Stopping)
訓練並非越久越好。提前停止是一種動態監控機制:在訓練過程中定期評估模型在驗證集上的表現。一旦驗證誤差停止改善甚至開始惡化,即使訓練誤差仍在下降,也立即終止訓練。這能有效捕捉模型表現最佳的時機,避免過度學習噪音。
6. 交叉驗證
除了作為診斷工具,交叉驗證也是防範過度擬合的重要手段。透過多輪訓練與驗證,能更準確評估模型的真實性能,並在超參數調整時選擇最穩定的組合,避免模型針對單一資料分割過度優化。
7. 集成學習 (Ensemble Learning)
集成學習的哲學是「集眾人智慧」。透過結合多個弱模型的預測結果,來產生更強大、更穩健的整體表現。
- 隨機森林:訓練多棵決策樹,每棵樹使用不同的資料子集與特徵,最終結果由多數決或平均決定,有效降低單一樹的過度擬合風險。
- 梯度提升(如 XGBoost、LightGBM):逐步修正前一個模型的錯誤,每一輪都專注於殘差,並內建正則化機制,能精準控制複雜度。
這些方法透過多樣性與協同效應,大幅提升模型的穩定性。
偏誤-變異數權衡 (Bias-Variance Trade-off):模型優化的核心思維
在機器學習中,模型的總誤差可分解為「偏誤」與「變異數」兩部分,兩者之間存在此消彼長的關係,稱為「偏誤-變異數權衡」。
- 偏誤:代表模型預測的平均值與真實值之間的系統性偏差。高偏誤意味著模型過於簡單,無法捕捉資料的真實結構,導致欠擬合。
- 變異數:代表模型對訓練資料微小變動的敏感度。高變異數表示模型過於複雜,對噪音反應過度,導致過度擬合。
過度擬合的模型通常具有「低偏誤、高變異數」:它在訓練資料上表現精準,卻對新資料極度不穩定。相反,欠擬合模型則是「高偏誤、低變異數」:它既學不好訓練資料,也無法預測新資料。真正的優化目標,是在兩者之間找到最佳平衡點,使總誤差最小化。所有防範過度擬合的策略,本質上都是在調整這項權衡,引導模型走向穩健與泛化。
過度擬合的真實代價:金融、醫療、智慧製造的案例解析
過度擬合不只是理論上的問題,它可能在關鍵領域釀成實際災難:
金融投資:回測美麗,實盤慘烈
許多量化交易策略在歷史資料回測中表現亮眼,年化報酬率驚人,但一投入實盤交易就迅速虧損。原因往往是策略過度擬合了特定市場週期、少數股票的偶然走勢,或是某段時間的特殊事件。一旦市場結構改變,這些「虛假規律」立刻失效。根據 Investopedia 的解釋,過度擬合是導致量化策略失敗的主因之一,投資者因此損失鉅額資金。
醫療診斷:誤診率飆升,影響患者生命
在癌症篩檢或疾病預測系統中,若模型過度擬合了某家醫院的設備成像特性或特定族群的生理特徵,當推廣至其他醫療機構時,準確率可能大幅下滑。例如,模型可能將某台X光機的固定雜訊誤認為腫瘤徵兆,導致健康患者被誤診。這不僅造成心理壓力,還可能引發不必要的治療,直接威脅生命安全。
智慧製造:誤報頻繁或關鍵故障遺漏
在工廠的預測性維護系統中,過度擬合的模型可能將感測器的短暫干擾誤判為設備故障,導致產線頻繁停機檢查,增加維護成本。更嚴重的是,它可能忽略真正的故障前兆,因為模型學到的是「表面特徵」而非「根本原因」。根據 IBM 的研究文章,在製造業導入AI時,確保模型的泛化能力是提升可靠性的關鍵挑戰,而過度擬合正是其中一大障礙。
總結:打造穩健 AI 模型的關鍵心法
過度擬合是機器學習實務中最常見的陷阱之一。它讓模型看似聰明,實則脆弱。本文從學生死記硬背的比喻出發,深入探討過度擬合的本質、成因與判斷方法,並與欠擬合進行對比。我們也解析了偏誤與變異數的權衡關係,這正是模型優化的核心思維。
更重要的是,我們整理了八種實用策略,包括增加資料、特徵工程、正則化、提前停止與集成學習等,幫助開發者主動防範過度擬合。這些方法不只是技術手段,更是一種設計哲學:讓模型學會「抓大放小」,專注於普遍規律,而非沉溺於細節。
最後,透過金融、醫療與製造業的真實案例,我們看到過度擬合可能帶來的經濟損失與安全風險。這提醒我們,模型的價值不在於訓練資料上的完美表現,而在於真實世界中的穩定與可靠。唯有持續驗證、謹慎調校,才能打造出真正值得信賴的AI系統。
過度擬合 (Overfitting) 在機器學習中具體指的是什麼?
過度擬合是指機器學習模型在訓練資料上表現得非常好,幾乎能完美預測訓練集中的每個樣本,包括其中的隨機噪音。然而,當模型面對未見過的新資料(測試集或實際應用數據)時,其預測性能卻會大幅下降。這代表模型喪失了「泛化能力」,無法將學到的知識有效地應用到真實世界中更廣泛的數據上。
過度擬合與欠擬合 (Underfitting) 的核心區別是什麼?
過度擬合與欠擬合是模型學習過程中的兩個極端:
- 過度擬合:模型過於複雜,記住了訓練數據中的噪音和細節,導致訓練集表現極佳,但測試集表現差。它具有「高變異數」和「低偏誤」。
- 欠擬合:模型過於簡單,未能充分捕捉訓練數據中的基本規律,導致訓練集和測試集表現均不理想。它具有「高偏誤」和「低變異數」。
模型出現過度擬合有哪些常見的原因?
模型過度擬合的常見原因包括:
- 模型複雜度過高:模型參數過多,自由度太高。
- 訓練數據量不足:數據量相對模型複雜度太少,模型容易將噪音視為規律。
- 數據中存在噪音:錯誤標記或異常值誤導模型學習。
- 特徵選擇不當或過多:引入不相關或冗餘特徵,增加了模型學習的難度。
我該如何透過觀察模型表現來判斷是否發生過度擬合?
判斷過度擬合的主要方法有:
- 觀察訓練集與測試集的性能差距:若訓練集性能遠優於測試集,則可能過度擬合。
- 學習曲線分析:繪製訓練誤差和驗證誤差隨訓練過程的變化圖,若兩者差距持續擴大,表示過度擬合。
- 交叉驗證結果:若模型在不同數據子集上的性能表現不穩定或差異大,也可能是過度擬合的跡象。
有哪些有效的方法可以避免或解決過度擬合的問題?
解決過度擬合的策略包括:
- 增加訓練數據量(或數據增強)。
- 特徵選擇與特徵工程。
- 降低模型複雜度(減少參數、層數,選擇更簡單的模型)。
- 使用正則化(L1、L2、Dropout)。
- 提前停止訓練。
- 應用交叉驗證。
- 採用集成學習方法(如隨機森林、梯度提升)。
正則化 (Regularization) 為什麼能夠緩解過度擬合?
正則化透過在模型的損失函數中加入一個額外的懲罰項,來限制模型參數(權重)的大小。它「懲罰」過大的權重值,促使模型學習更簡單、更平滑的決策邊界,從而降低模型的複雜度。這樣可以防止模型過度依賴訓練數據中的特定特徵或噪音,使其更傾向於捕捉普遍性的規律,從而提升泛化能力,緩解過度擬合。
偏誤-變異數權衡 (Bias-Variance Trade-off) 對於理解過度擬合有何重要性?
偏誤-變異數權衡是模型優化的核心概念。過度擬合的模型通常具有「高變異數」和「低偏誤」——它能很好地擬合訓練數據(低偏誤),但對數據的微小變化非常敏感(高變異數)。理解這種權衡能幫助我們在模型選擇和調整超參數時,找到一個平衡點,既能充分學習數據模式(降低偏誤),又不過度學習噪音(降低變異數),以達到最佳的泛化性能。
在金融預測或醫療診斷等實際應用中,過度擬合會帶來哪些潛在危害?
過度擬合在實際應用中可能造成嚴重後果:
- 金融投資:過度擬合的交易策略在歷史回測中表現驚人,但在實際市場中可能導致巨額虧損。
- 醫療診斷:過度擬合的診斷模型可能對特定數據集表現良好,但在推廣應用時誤診率飆升,影響患者生命。
- 智慧製造:過度擬合的預測模型可能導致設備故障預警頻繁誤報或關鍵故障被遺漏,造成生產中斷和經濟損失。
除了增加數據量,還有哪些數據處理技術可以幫助減少過度擬合?
除了增加數據量,以下數據處理技術也能有效減少過度擬合:
- 特徵選擇:移除不相關、冗餘或噪音過大的特徵。
- 特徵工程:創造更具代表性、更有意義的新特徵。
- 數據增強 (Data Augmentation):透過對現有數據進行轉換(如圖像旋轉、文本替換),生成新的訓練樣本。
- 數據清理:處理異常值、缺失值和錯誤標記,減少數據中的噪音。
對於初學者來說,理解過度擬合最簡單的比喻是什麼?
對於初學者來說,理解過度擬合最簡單的比喻是「學生死記硬背考試題目」。一個學生為了考試,不去理解課本上的核心知識,而是將過去所有考卷上的題目和答案連同細節(甚至錯別字)都記下來。結果,當考試內容稍有變化或換了個提問方式時,他就會考得很差,因為他記住的是「具體的考題細節」,而不是「普遍的解題規律」。